
Data Flow Map
v1.1 dev-preview · stable on PyPI: 1.0.3
Outside — external data source
Core — AAanalysis CPP pipeline
Wrapped — AAanalysis class + external engine (logo)


Protein sequences
UniProt · biopython


Protein embeddings
ESM-2 · ProtT5


Protein structures
AlphaFold · PDB
Protein annotations
UniProt · PTMs
load_dataset · read_fasta
→ df_seq
EmbeddingPreprocessor
→ dict_num
StructurePreprocessor
→ dict_num
AnnotationPreprocessor
→ dict_num
load_scales · AAclust
→ df_scales · df_cat
SequenceFeature.get_df_parts
→ df_parts
SequenceFeature.get_split_kws
→ split_kws
NumericalFeature.get_parts
→ dict_num_parts
CPP.run
Part × Split × Scale
→ df_feat
CPP.run_num
Part × Split
→ df_feat
SequenceFeature.feature_matrix
→ X
+ df_feat → models

TreeModel
predict.predict_proba
global importance.add_feat_importance
for group comparison

ShapModel
local impact.add_feat_impact
per sequence

SeqMut · SeqOpt
design · directed evolution (DEAP)
sequences
embeddings
structure
annotations
Scale
Part
Split
Split
Part
predict
design
explain
global
local
Core:
df_seq (load_dataset / read_fasta) → df_parts;
split_kws and df_scales are built directly. CPP.run combines
Part × Split × Scale; CPP.run_num uses numeric values
(embeddings ESM-2/ProtT5 or AlphaFold/PDB structures → dict_num → dict_num_parts).
Both produce df_feat → X.
Wrapped (amber, outside): TreeModel (scikit-learn / PyTorch) predicts and gives global feature importance,
ShapModel (SHAP) gives local feature impact per sequence, and SeqMut · SeqOpt (DEAP) designs variants — all take X and df_feat.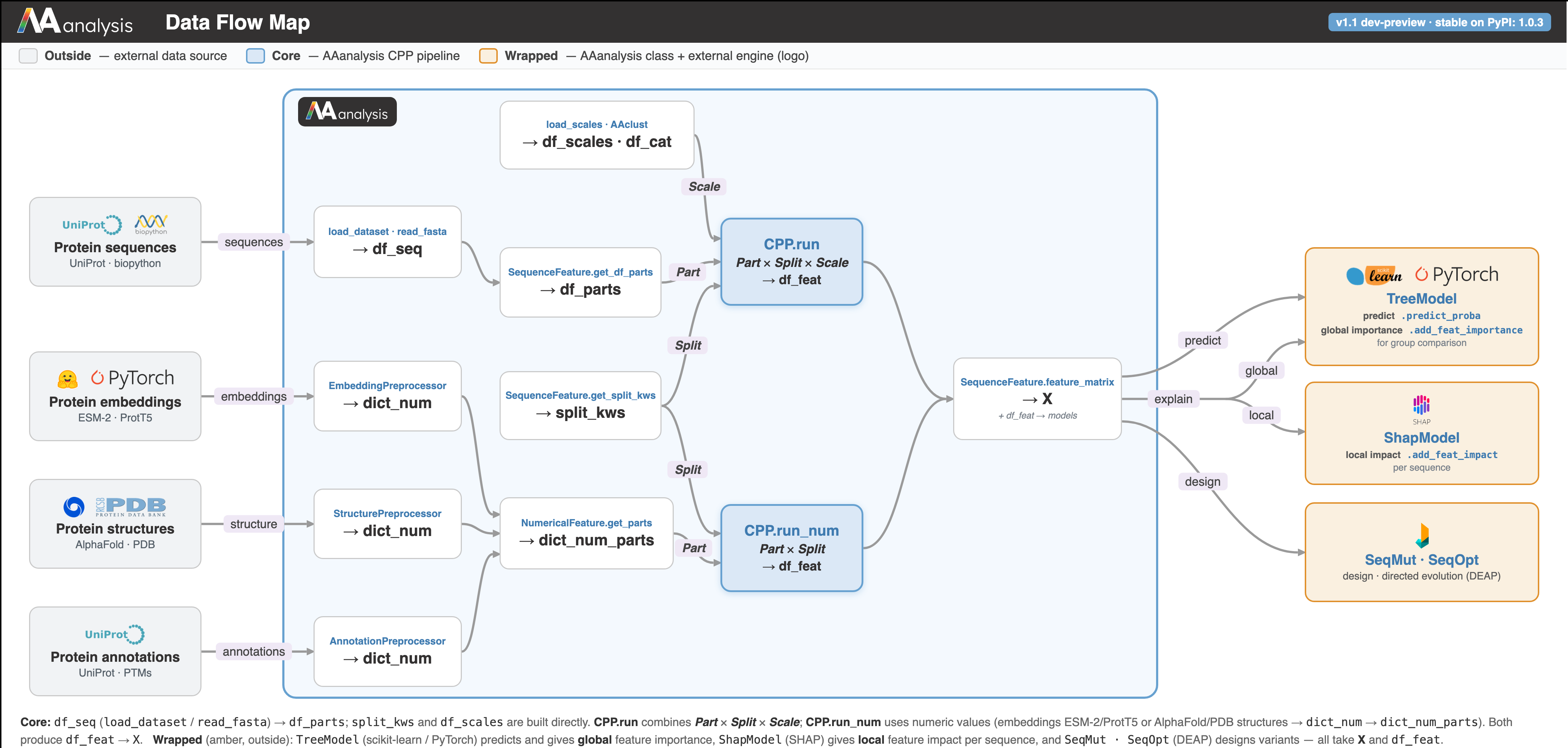{kind=link}