dPULearn: Learning From Unbalanced Data
In the life sciences, the prevalence of unbalanced and small datasets often leads to challenges in machine learning, particularly when dealing with a rare class of interest. Typically, binary classification involves labeled positive and negative data. However, in scenarios where negative samples are scarce, conventional data augmentation methods like SMOTE may fall short due to generating artificial samples. This issue is especially pertinent in fields like protein sequence prediction, where even minor alterations can lead to significant biological implications. A practical solution is to harness the abundance of unlabeled data to identify negative samples, a strategy that becomes essential when obtaining a balanced dataset is challenging.
Provided by
In AAanalysis this is the dPULearn class. See the
API reference and the Evaluating PU Learning
chapter for how the identified negatives are assessed.
What is PU learning?
Positive-Unlabeled (PU) learning, a subfield of machine learning, is tailored for situations with only positive and unlabeled data. It is gaining relevance in bioinformatics and similar fields, where negative data often remain unlabeled and undiscovered. PU learning algorithms aim to identify negative data from unlabeled data based on statistical comparison with the positive data, coupled with iterative learning strategies. This approach adeptly handles the inherent data asymmetry in applications where labeled negatives are unattainable.
dPULearn: Learning reliably from Unbalanced and Small Data
dPULearn (deterministic Positive-Unlabeled Learning) is a non-stochastic PU Learning algorithm for identifying reliably negative samples from unlabeled data, as introduced in [Breimann25].
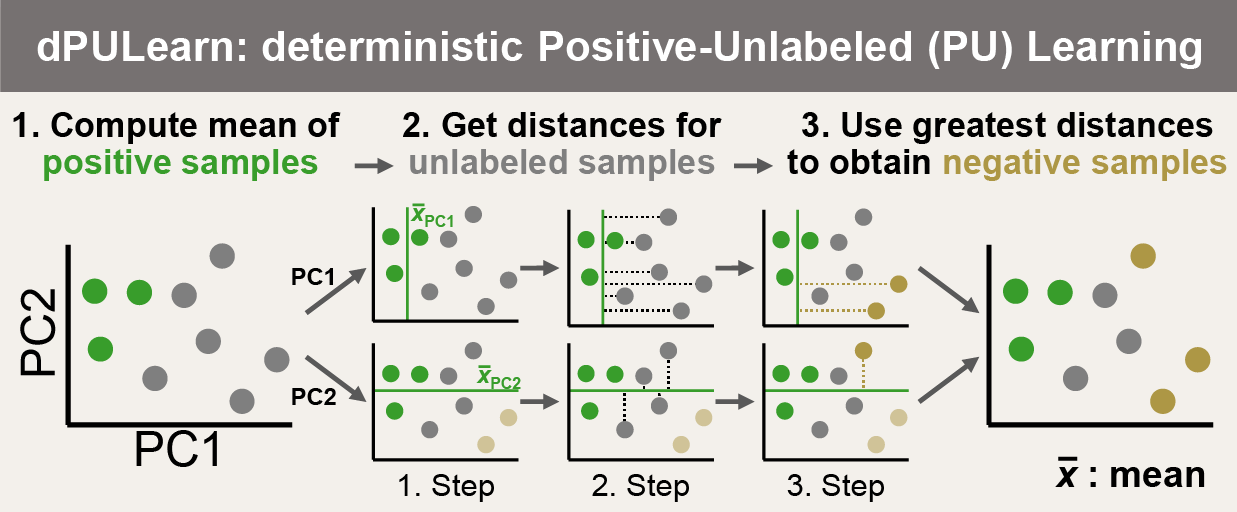
Scheme of dPULearn algorithm, adapted from [Breimann25].
See the Evaluating PU Learning chapter for how the identified negatives and overall predictive performance are assessed.