find_features
- find_features(labels, df_seq, search='balanced', simplify=True, model='svm', cv=5, metric='balanced_accuracy', selection_scope='global', kws=None, subcategories=None, top_n=None, label_test=1, label_ref=0, name_test='TEST', name_ref='REF', plot=True, random_state=None, n_jobs=None, verbose=False)[source]
Identify discriminating features in one call via a staged, interpretable CPP AutoML search.
The search is staged so its cost stays interpretable. Stage 1 cross-validates the full Cartesian Part × Split × Scale grid (at a reference
n_filter) and ranks each axis by its marginal-mean impact; Stage 2 refines only the single highest-impact axis againstn_filter(the others pinned at the stage optimum); Stage 3 refines the winning feature set withCPP.simplify()and recursive feature elimination. Selection is multi-objective: within each stage the Pareto-optimal-then-simplest configuration across allmetricwins, scored by the average cross-validated performance of one or moremodels. The winner is then ranked by tree-based importance and drawn as the CPP feature map. Atsearch="fast"no search is run — the result is byte-identical to the explicit single-CPP path.Warning
Experimental. This
aaanalysis.pipe(ap) golden pipeline is under active development; its API and its reported cross-validation scores may change between minor releases without the usual deprecation cycle. By default (selection_scope="global") feature selection runs on the full labeled set, so the reported scores are an in-sample (optimistic) ranking signal rather than a held-out generalization estimate; passselection_scope="fold"for the honest nested regime. Pin a version if you depend on the current behaviour.- Parameters:
labels (array-like, shape (n_samples,)) – Class labels for the samples (typically, 1=positive/test, 0=negative/reference).
df_seq (pd.DataFrame, shape (n_samples, n_seq_info)) – Sequence DataFrame, row-aligned to
labels. Required, because the Part regions are a swept lever and must be (re)built from the sequences viaSequenceFeature.get_df_parts().search (str, default="balanced") – Search effort:
"fast"(single default configuration, no search),"balanced"(sweep the Split levers + Scale + symmetric JMD lengthn_jmd+n_filter), or"exhaustive"(also sweep the Part region set and the performance-ranked scale sets, with a finer grid and a widern_jmdrange).simplify (bool, default=True) – If
True, refine the winning feature set withCPP.simplify()(kept only if it is not Pareto-dominated).model (str, estimator, or list, default="svm") – Selection model(s):
"svm","rf","log_reg", a scikit-learn estimator, or a list of these. A list averages the cross-validated scores across models.cv (int, default=5) – Number of cross-validation folds for the selection score, must be > 1.
metric (str or list of str, default="balanced_accuracy") – Cross-validation scoring metric(s). A list triggers multi-objective Pareto selection.
selection_scope ({"global", "fold"}, default="global") –
Where CPP feature selection happens relative to the cross-validation.
"global"(default): CPP selects features on the full labeled set and the model is cross-validated on that fixed feature matrix. Fast, but the reported scores are an in-sample (optimistic) ranking signal — feature selection has seen the test fold."fold": an honest nested regime — within every fold of every configuration score, CPP re-selects features on the train split only, the model is fit on the train features and scored on the held-out fold. This removes the selection leakage, so thedf_evalscores are held-out generalization estimates (typically lower). It re-runs CPP per fold, so it is much more expensive; pair it withsearch="fast"/"balanced". The returneddf_featis always the winning configuration refit on all data (outer-CV semantics). Nesting applies to the configuration-selection scores (the Stage-1/2 grid and the"fast"single-configuration score); the winner’s second-step refinement (CPP.simplify()+ recursive feature elimination) runs on all data in both scopes, so no refinement capability is lost in"fold"mode.
kws (dict, optional) – Bounded power-user overrides; each pins a swept lever to a single value (unknown keys raise). Recognized keys:
n_explain,n_split_max(maxSegmentsplits),len_max(maxPatternspan),n_filter,n_jmd(the symmetric JMD lengthjmd_n_len = jmd_c_len),simplify_strategy,max_cor,max_overlap. For free peptides / short parts (no flanking context), passkws={"n_jmd": 0}so no JMD is carved out; the search then uses TMD-only parts (the whole peptide is one part, rather than half-TMD fragments) and caps the swept ``n_split_max`` range to the shortest part length (deduped), with aUserWarning. The split config also auto-caps to the shortest part (Pattern/PeriodicPatternthat cannot fit are dropped andn_split_maxis clamped). On normal (long-part) inputs the range cap is a no-op. Lowern_split_max/len_maxyourself to control which splits are used.subcategories (list of str, optional) – AAontology subcategories to restrict the scale sets to. If
None, all scales of the grade.top_n (int, optional) – If given, keep only the top
top_nfeatures (after importance ranking).label_test (int, default=1) – Class label of the test/positive group passed to
CPP.run().label_ref (int, default=0) – Class label of the reference/negative group passed to
CPP.run().name_test (str, default="TEST") – Display name of the test/positive group in the feature map.
name_ref (str, default="REF") – Display name of the reference/negative group in the feature map.
plot (bool, default=True) – If
True, draw the CPP feature map (returned asax) and the publication eval figures (attached asax.eval); ifFalse, draw nothing and returnNone.random_state (int, optional) – The seed used by the random number generator. If a positive integer, results of stochastic processes are reproducible.
n_jobs (int, optional) – Number of CPU cores (>=1) for the sweep and feature-matrix builds. If
None, the optimized number is used.verbose (bool, default=False) – If
True, verbose progress information is printed.
- Returns:
df_feat (pd.DataFrame) – Feature DataFrame of the selected configuration in the canonical CPP schema, ranked by tree-based importance.
ax (matplotlib.axes.Axes or None) – The feature-map
Axesifplot=True, elseNone. When a search was run, the publication eval figures are attached asax.eval(a list ofmatplotlib.figure.Figure; empty for a single-configurationfastsearch) — seeplot_eval().df_eval (pd.DataFrame) – Per-configuration sweep table: the configuration descriptors, one
<metric>_mean/<metric>_stdcolumn per metric, plusstage,is_pareto(Pareto-optimal within its stage),rank, andis_selected(the single winner).
See also
CPPGridfor the configuration sweep this pipeline drives.CPP.run()andCPP.simplify()for the underlying feature engineering.CPPPlot.feature_map()for the visualization.
Examples
The
aaanalysis.pipe(ap) module provides high-level golden pipelines — stateless, one-call wrappers over the AAanalysis primitives.ap.find_featuresruns a staged, interpretable CPP AutoML search: Stage 1 cross-validates the full Cartesian Part × Split × Scale grid and ranks each axis by its marginal-mean impact; Stage 2 refines the single highest-impact axis againstn_filter; Stage 3 refines the winning feature set (CPP.simplify+ recursive feature elimination). Selection is multi-objective — within each stage the Pareto-optimal-then-simplest configuration across all metrics wins, scored by the averaged cross-validated performance of one or more models. It returns(df_feat, ax, df_eval).import matplotlib.pyplot as plt import aaanalysis as aa import aaanalysis.pipe as ap aa.options["verbose"] = False aa.plot_settings() df_seq = aa.load_dataset(name="DOM_GSEC", n=20) labels = df_seq["label"].to_list() aa.display_df(df_seq, n_rows=10, show_shape=True)
DataFrame shape: (40, 9)
entry gene sequence label tmd_start tmd_stop jmd_n tmd jmd_c 1 Q14802 FXYD3 MQKVTLGLLVFLAGF...PGETPPLITPGSAQS 0 37 59 NSPFYYDWHS LQVGGLICAGVLCAMGIIIVMSA KCKCKFGQKS 2 Q86UE4 MTDH MAARSWQDELAQQAE...SPKQIKKKKKARRET 0 50 72 LGLEPKRYPG WVILVGTGALGLLLLFLLGYGWA AACAGARKKR 3 Q969W9 PMEPA1 MHRLMGVNSTAAAAA...AIWSKEKDKQKGHPL 0 41 63 FQSMEITELE FVQIIIIVVVMMVMVVVITCLLS HYKLSARSFI 4 P53801 PTTG1IP MAPGVARGPTPYWRL...GLFKEENPYARFENN 0 97 119 RWGVCWVNFE ALIITMSVVGGTLLLGIAICCCC CCRRKRSRKP 5 Q8IUW5 RELL1 MAPRALPGSAVLAAA...EVPATPVKRERSGTE 0 59 81 NDTGNGHPEY IAYALVPVFFIMGLFGVLICHLL KKKGYRCTTE 6 P01135 TGFA MVPSAGQLALFALGI...LLKGRTACCHSETVV 0 99 121 AVVAASQKKQ AITALVVVSIVALAVLIITCVLI HCCQVRKHCE 7 O43914 TYROBP MGGLEPCSRLLLLPL...SDVYSDLNTQRPYYK 0 42 64 DCSCSTVSPG VLAGIVMGDLVLTVLIALAVYFL GRLVPRGRGA 8 P05556 ITGB1 MNLQPIFWIGLISSV...KSAVTTVVNPKYEGK 0 729 751 ENPECPTGPD IIPIVAGVVAGIVLIGLALLLIW KLLMIIHDRR 9 P16234 PDGFRA MGTSHPAFLVLGCLL...DIGIDSSDLVEDSFL 0 527 549 VAPTLRSELT VAAAVLVLLVIVIISLIVLVVIW KQKPRYEIRW 10 P50895 BCAM MEPPDAPAQARGAPR...SGGARGGSGGFGDEC 0 549 571 TVSPQTSQAG VAVMAVAVSVGLLLLVVAVFYCV RRKGGPCCRQ Fast runs a single default configuration — no search — so the result is byte-identical to the explicit CPP chain.
df_evalthen holds one row (the single configuration with its cross-validatedbalanced_accuracy):df_feat, ax, df_eval = ap.find_features(labels=labels, df_seq=df_seq, search="fast", plot=False, random_state=42, n_jobs=1) aa.display_df(df_eval, n_rows=10, show_shape=True)
DataFrame shape: (1, 15)
stage list_parts split_types pattern_mode n_split_max scale n_jmd n_filter n_features selection_scope balanced_accuracy_mean balanced_accuracy_std is_pareto rank is_selected 1 single tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern...PeriodicPattern p1+p2 15 explain:30 10 100 81 global 0.950000 0.100000 True 1 True By default (
selection_scope="global") CPP selects features on the full labeled set, so the reported scores are an in-sample (optimistic) ranking signal. Passselection_scope="fold"for the honest nested regime: within every fold of every configuration score, CPP re-selects features on the train split only and the model is scored on the held-out fold, so thedf_evalscores are held-out (typically lower) generalization estimates. The returneddf_featis still the winner refit on all data.df_feat, ax, df_eval = ap.find_features(labels=labels, df_seq=df_seq, search="fast", selection_scope="fold", plot=False, random_state=42, n_jobs=1) aa.display_df(df_eval, n_rows=10, show_shape=True)
DataFrame shape: (1, 15)
stage list_parts split_types pattern_mode n_split_max scale n_jmd n_filter n_features selection_scope balanced_accuracy_mean balanced_accuracy_std is_pareto rank is_selected 1 single tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern...PeriodicPattern p1+p2 15 explain:30 10 100 81 fold 0.725000 0.145774 True 1 True Balanced runs the staged search.
df_evalis the per-stage sweep table — thesensitivityStage-1 grid, then_filterStage-2 refinement of the dominant axis, and therefinerows — each carryingis_pareto(Pareto-optimal within its stage) and oneis_selectedwinner (here the Split sweep is pinned viakwsto keep the example quick):df_feat, ax, df_eval = ap.find_features(labels=labels, df_seq=df_seq, search="balanced", kws={"n_explain": 30, "n_split_max": 15}, plot=False, random_state=42, n_jobs=1) aa.display_df(df_eval, n_rows=10, show_shape=True)
DataFrame shape: (22, 15)
stage list_parts split_types pattern_mode n_split_max scale n_jmd n_filter n_features selection_scope balanced_accuracy_mean balanced_accuracy_std is_pareto is_selected rank 1 sensitivity tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 150 150 global 0.975000 0.050000 True False 1 2 n_filter tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 125 125 global 0.975000 0.050000 True False 2 3 n_filter tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 150 150 global 0.975000 0.050000 True False 3 4 refine tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 125 101 global 0.975000 0.050000 True False 4 5 refine tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 125 63 global 0.975000 0.050000 True True 5 6 sensitivity tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment none 15 explain:30 10 150 150 global 0.950000 0.100000 False False 6 7 sensitivity tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,PeriodicPattern p2 15 explain:30 10 150 150 global 0.950000 0.061237 False False 7 8 n_filter tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 50 50 global 0.950000 0.100000 False False 8 9 n_filter tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,Pattern p1 15 explain:30 10 100 100 global 0.950000 0.100000 False False 9 10 sensitivity tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment none 15 explain:30 6 150 150 global 0.925000 0.150000 False False 10 Selection is multi-objective. Pass several
models (their cross-validated scores are averaged) and severalmetrics (the winner is Pareto-optimal across them, then simplest).df_evalgains one<metric>_mean/_stdcolumn per metric and anis_paretoflag.cvsets the folds;simplifytoggles the refinement;subcategories/top_nrestrict the scales / the returned features;label_test/label_refset the groups;exhaustiveadditionally sweeps the Part regions and the performance-ranked scale sets:subs = sorted(aa.load_scales(name="scales_cat")["subcategory"].unique())[:15] df_feat, ax, df_eval = ap.find_features(labels=labels, df_seq=df_seq, search="balanced", model=["svm", "rf"], metric=["balanced_accuracy", "f1"], cv=5, simplify=True, kws={"n_explain": 30, "n_split_max": 15, "n_filter": 25}, subcategories=subs, top_n=15, label_test=1, label_ref=0, plot=False, random_state=42, n_jobs=1, verbose=False) aa.display_df(df_eval[df_eval["is_pareto"]], n_rows=10, show_shape=True)
DataFrame shape: (3, 17)
stage list_parts split_types pattern_mode n_split_max scale n_jmd n_filter n_features selection_scope balanced_accuracy_mean balanced_accuracy_std f1_mean f1_std is_pareto is_selected rank 1 sensitivity tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,PeriodicPattern p2 15 explain:30 10 25 25 global 0.937500 0.100000 0.943889 0.090613 True False 1 3 n_filter tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,PeriodicPattern p2 15 explain:30 10 25 25 global 0.937500 0.100000 0.943889 0.090613 True False 3 5 refine tmd,jmd_n_tmd_n,tmd_c_jmd_c Segment,PeriodicPattern p2 15 explain:30 10 25 14 global 0.937500 0.100000 0.943889 0.090613 True True 5 With
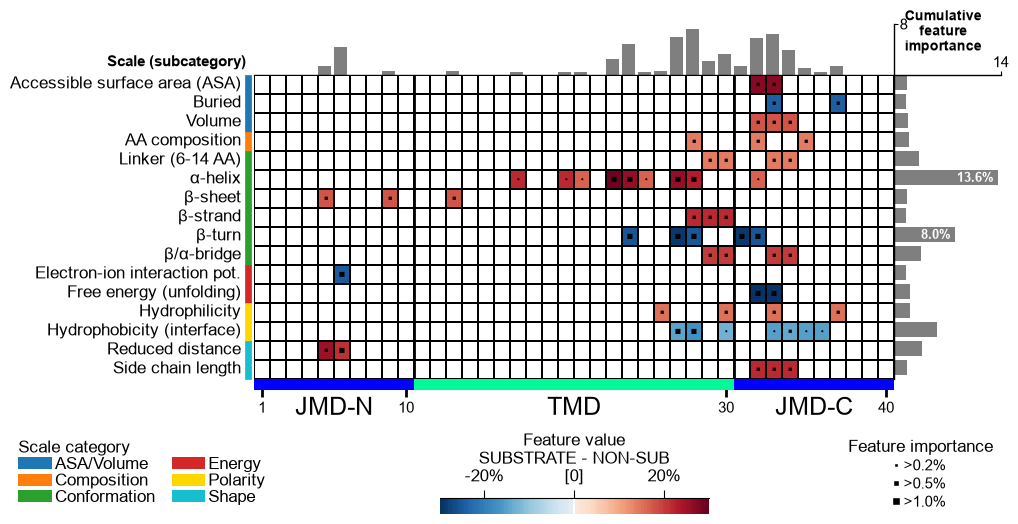
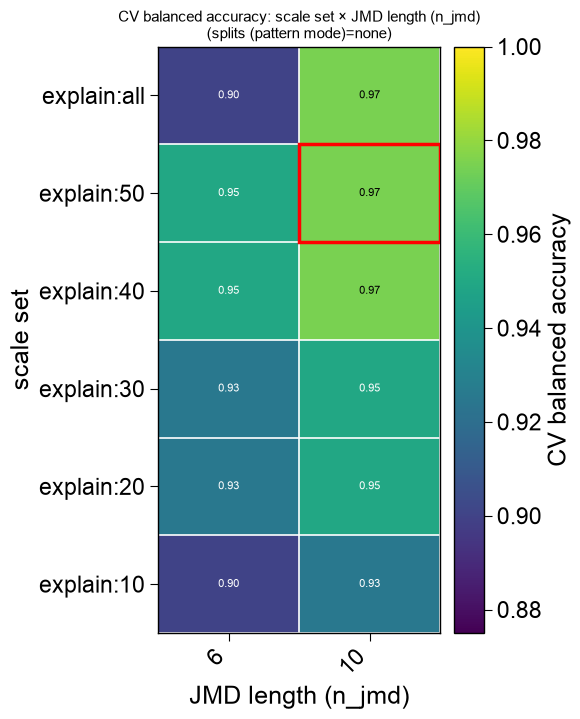
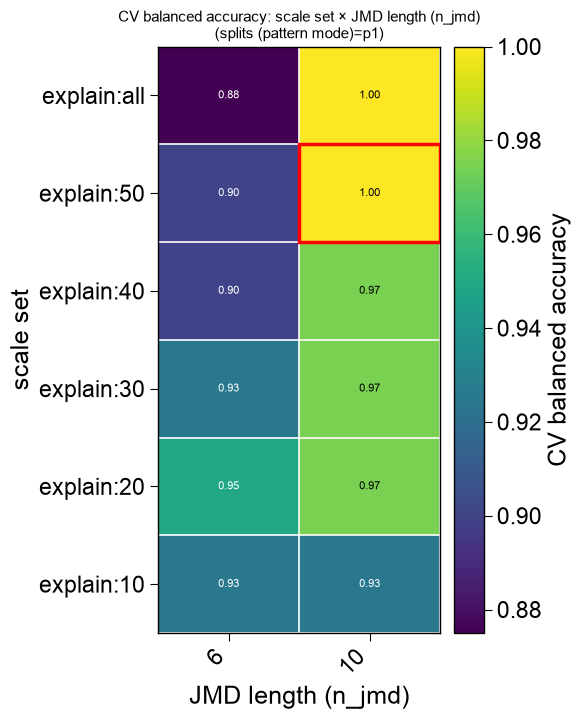
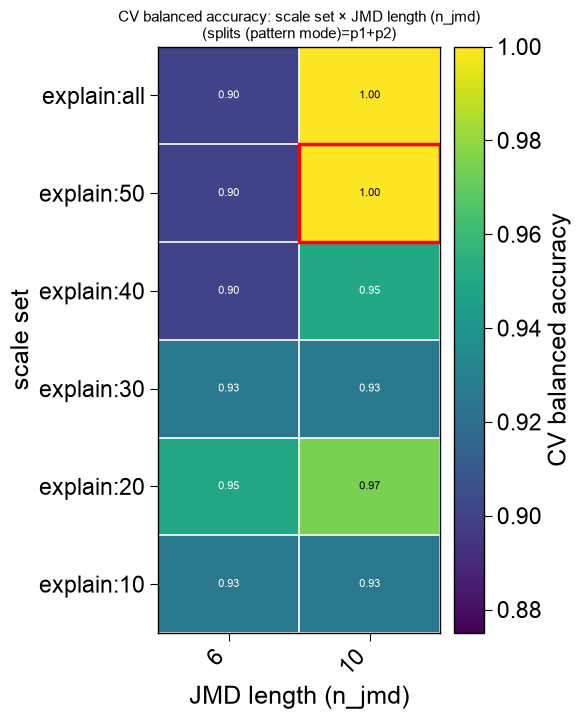
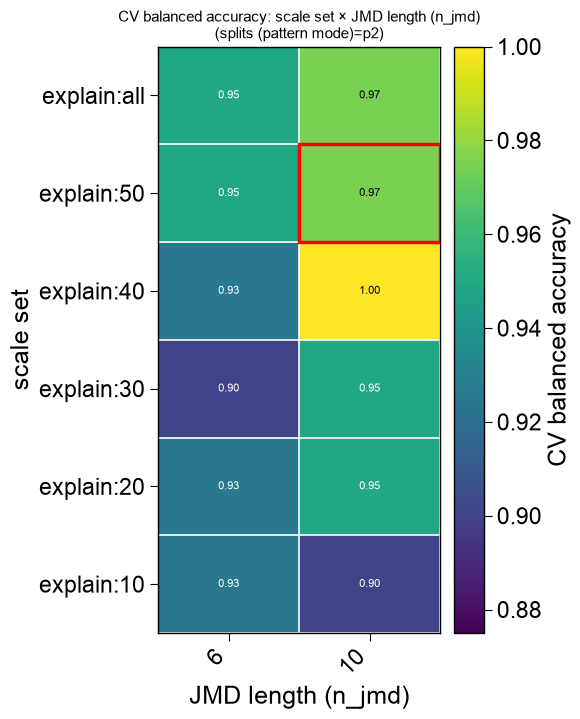
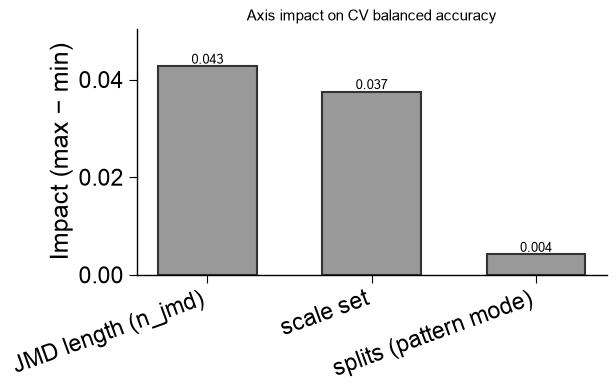
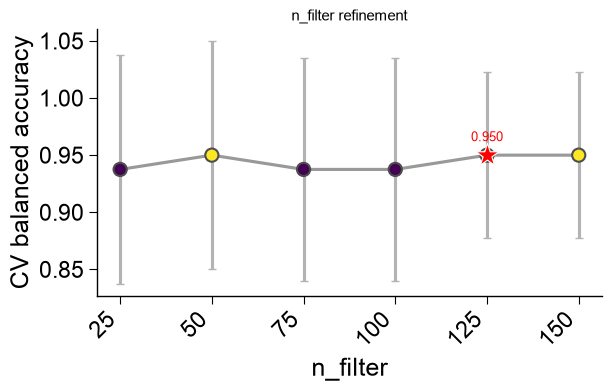
plot=Truethe winning features are drawn as the CPP feature map (the returnedax), and — when a search was run — the sweep is decomposed into publication-ready eval figures attached asax.eval: a series of 2Dviridisheatmaps (the two most-informative axes per panel, the least as the slice), a marginal-impact panel, and ann_filterpanel.name_test/name_reflabel the two groups; a singleplt.show()renders the feature map and every eval figure, and each figure can be saved individually for a paper (ax.eval[0].savefig(...)):df_feat, ax, df_eval = ap.find_features(labels=labels, df_seq=df_seq, search="balanced", kws={"n_split_max": 15}, top_n=25, plot=True, name_test="SUBSTRATE", name_ref="NON-SUB", random_state=42, n_jobs=1) print(f"feature map + {len(ax.eval)} publication eval figures (ax.eval)") plt.show()
feature map + 6 publication eval figures (ax.eval)