predict_samples
- predict_samples(list_df_feat, df_seq, labels, models=None, n_cv=5, plot=True, figsize=None, dict_color=None, baseline=None, random_state=None, n_jobs=None, verbose=False)[source]
Train and compare predictors across feature sets and models in one call.
A thin, stateless facade over the explicit primitive path. For every combination of a feature set (in
list_df_feat) and a model (inmodels), it rebuilds the feature matrixXfrom the feature identifiers (viaSequenceFeature.feature_matrix()), cross-validates the model, and refits it on all samples to give a deployable predictor. The fitted predictors are returned as a dictionary together with a tidy cross-validated comparison table.Warning
Experimental. This
aaanalysis.pipe(ap) golden pipeline is under active development; its API (signatures, defaults, return objects) may change between minor releases without the usual deprecation cycle. Pin a version if you depend on the current behaviour.- Parameters:
list_df_feat (pd.DataFrame or list or dict) – One or several feature sets. A single feature DataFrame (with a
featurecolumn of feature identifiers, e.g. fromCPP.run()orload_features()), a list of such DataFrames, or a{name: df_feat}dict. Lists / single frames are auto-named (feat1…).df_seq (pd.DataFrame, shape (n_samples, n_seq_info)) – Sequence DataFrame, row-aligned to
labels. The sequence parts are derived from it once and shared across all feature sets.labels (array-like, shape (n_samples,)) – Class labels for the samples (typically, 1=positive/test, 0=negative/reference).
models (str, estimator, list, or dict, optional) – The models to train. A scikit-learn estimator instance, a model-name string (one of
'rf','svm','log_reg','extra_trees'), a list of either (names taken from the estimator class), or a{name: estimator}dict. IfNone, a core default set is compared: random forest, extra trees, SVM, and logistic regression.n_cv (int, default=5) – Number of cross-validation folds, must be > 1 and <= the smallest class count.
plot (bool, default=True) –
If
True, draw the model comparison bar plot (hue = model, one bar group per metric, with cross-validationstderror bars) from the comparison table and return itsAxes.Added in version 1.1.0.
figsize (tuple, optional) –
Figure size of the comparison plot; a per-kind default is used when
None.Added in version 1.1.0.
dict_color (dict, optional) –
Mapping
model -> colorfor the comparison-plot bars; defaults to the house palette. When more than one feature set is compared, the bars are labelled"<feature_set> · <model>", so keys must match those composite labels.Added in version 1.1.0.
baseline (int or float, optional) –
y-value of a dashed chance line on the comparison plot (e.g.
0.5); none whenNone.Added in version 1.1.0.
random_state (int, optional) – The seed used by the random number generator. If a positive integer, results of stochastic processes are reproducible. Injected into each model only where the estimator exposes a
random_stateparameter and the user left it unset.n_jobs (int, optional) – Number of CPU cores (>=1) for building the feature matrix. If
None, the optimized number is used.verbose (bool, default=False) – If
True, verbose progress information is printed.
- Returns:
predictors (dict) – The fitted predictors, keyed by
(feature_set, model). Each value is the corresponding scikit-learn estimator refit on all samples.fig_ax (matplotlib.axes.Axes or None) – The comparison-plot
Axeswhenplot=True, elseNone(keeping the uniform(results, figs, evals)pipeline return shape).df_eval (pd.DataFrame, shape (n_feature_sets * n_models, n_eval_info)) – Comparison table, one row per
(feature_set, model): the descriptors,n_features, one<metric>_mean/<metric>_stdcolumn pair per metric (balanced_accuracy, accuracy, f1, precision, recall, roc_auc),is_shap_ready(the predictor exposes feature importances, so it can feedexplain_features()), andis_best(the single highestbalanced_accuracy_meanrow).
See also
SequenceFeature.feature_matrix()for buildingXfrom feature identifiers.find_features()for producing adf_featfeature set to predict from.explain_features()for SHAP-explaining a SHAP-ready predictor’s feature set.
Examples
The
aaanalysis.pipe(ap) module provides high-level golden pipelines — stateless, one-call wrappers over the AAanalysis primitives.ap.predict_samplestrains and compares predictors across one or more feature sets and scikit-learn models: for every (feature set × model) combination it rebuilds the feature matrix, cross-validates the model, and refits it on all samples. It returns the uniform pipeline triple(predictors, figs, df_eval)— a dict of fitted predictors keyed by(feature_set, model),figs(alwaysNonehere, since prediction draws no plot), and a tidy cross-validated comparison table (see [Breimann25]).We first load the
DOM_GSECexample dataset, its labels, and a small feature set:import aaanalysis as aa import aaanalysis.pipe as ap import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.linear_model import LogisticRegression aa.options["verbose"] = False df_seq = aa.load_dataset(name="DOM_GSEC", n=25) labels = df_seq["label"].to_list() df_feat = aa.load_features().head(10) aa.display_df(df_feat, n_rows=10, show_shape=True)
DataFrame shape: (10, 15)
feature category subcategory scale_name scale_description abs_auc abs_mean_dif mean_dif std_test std_ref p_val_mann_whitney p_val_fdr_bh positions feat_importance feat_importance_std 1 TMD_C_JMD_C-Seg...3,4)-KLEP840101 Energy Charge Charge Net charge (Kle...n et al., 1984) 0.244000 0.103666 0.103666 0.106692 0.110506 0.000000 0.000000 31,32,33,34,35 0.970400 1.438918 2 TMD_C_JMD_C-Seg...3,4)-FINA910104 Conformation α-helix (C-cap) α-helix termination Helix terminati...n et al., 1991) 0.243000 0.085064 0.085064 0.098774 0.096946 0.000000 0.000000 31,32,33,34,35 0.000000 0.000000 3 TMD_C_JMD_C-Seg...6,9)-LEVM760105 Shape Side chain length Side chain length Radius of gyrat... (Levitt, 1976) 0.233000 0.137044 0.137044 0.161683 0.176964 0.000000 0.000001 32,33 1.554800 2.109848 4 TMD_C_JMD_C-Seg...3,4)-HUTJ700102 Energy Entropy Entropy Absolute entrop...Hutchens, 1970) 0.229000 0.098224 0.098224 0.106865 0.124608 0.000000 0.000001 31,32,33,34,35 3.111200 3.109955 5 TMD_C_JMD_C-Seg...6,9)-RADA880106 ASA/Volume Volume Accessible surface area (ASA) Accessible surf...olfenden, 1988) 0.223000 0.095071 0.095071 0.114758 0.132829 0.000000 0.000002 32,33 0.000000 0.000000 6 TMD_C_JMD_C-Seg...2,3)-KLEP840101 Energy Charge Charge Net charge (Kle...n et al., 1984) 0.222000 0.058671 0.058671 0.064895 0.069547 0.000000 0.000001 27,28,29,30,31,32,33 0.000000 0.000000 7 TMD_C_JMD_C-Seg...4,5)-FAUJ880109 Energy Isoelectric point Number hydrogen bond donors Number of hydro...e et al., 1988) 0.215000 0.146661 0.146661 0.174609 0.188034 0.000000 0.000004 33,34,35,36 1.032400 1.510722 8 TMD_C_JMD_C-Seg...3,4)-JANJ780101 ASA/Volume Accessible surface area (ASA) ASA (folded protein) Average accessi...n et al., 1978) 0.215000 0.124317 0.124317 0.166309 0.153364 0.000000 0.000004 31,32,33,34,35 1.080400 1.296094 9 TMD_C_JMD_C-Seg...,10)-WILM950103 Polarity Hydrophobicity (interface) Hydrophobicity (interface) Hydrophobicity ...e et al., 1995) 0.212000 0.141305 -0.141305 0.168603 0.217235 0.000000 0.000005 33,34 1.747200 2.150664 10 TMD_C_JMD_C-Seg...6,9)-AURR980110 Conformation α-helix α-helix (middle) Normalized posi...ora-Rose, 1998) 0.211000 0.125350 0.125350 0.160819 0.174121 0.000000 0.000005 32,33 1.788800 2.700803 Default comparison. With
models=Nonea core set of four scikit-learn models is compared. Withplot=True(the default)predict_samplesalso draws the model comparison bar plot (hue = model, one bar group per metric, with cross-validationstderror bars) and returns itsAxes:# plot=True (default) draws the model comparison and returns its Axes in the middle slot. predictors, ax, df_eval = ap.predict_samples(df_feat, df_seq, labels=labels, random_state=42) aa.display_df(df_eval, n_rows=10, show_shape=True) plt.tight_layout() plt.show()
DataFrame shape: (4, 17)
/Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn(
feature_set model n_features balanced_accuracy_mean balanced_accuracy_std accuracy_mean accuracy_std f1_mean f1_std precision_mean precision_std recall_mean recall_std roc_auc_mean roc_auc_std is_shap_ready is_best 1 features RandomForest 10 0.800000 0.063246 0.800000 0.063246 0.766104 0.110364 0.886667 0.093333 0.720000 0.203961 0.816000 0.093295 True False 2 features ExtraTrees 10 0.780000 0.074833 0.780000 0.074833 0.751558 0.109729 0.860000 0.127192 0.720000 0.203961 0.820000 0.071554 True False 3 features SVM 10 0.820000 0.074833 0.820000 0.074833 0.815051 0.072744 0.860000 0.127192 0.800000 0.126491 0.888000 0.092607 False True 4 features LogReg 10 0.780000 0.074833 0.780000 0.074833 0.780606 0.081348 0.770000 0.058119 0.800000 0.126491 0.904000 0.089800 False False 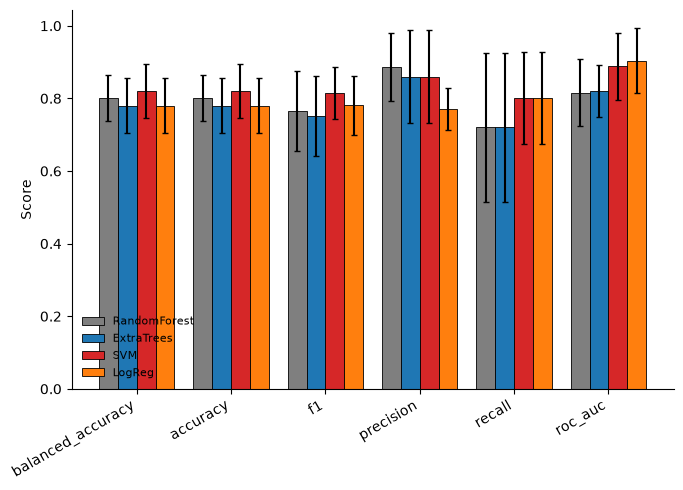
Reading ``df_eval``. One row per
(feature_set, model):feature_set/model— the combination’s names (also the keys of the returnedpredictorsdict).n_features— the number of features in that set.<metric>_mean/<metric>_std— the cross-validated mean and standard deviation of each metric:balanced_accuracy(the headline, imbalance-aware),accuracy,f1,precision,recall,roc_auc.is_shap_ready— whether the fitted predictor exposes feature importances (tree-based models), so it can feedap.explain_features.is_best— the single highestbalanced_accuracy_meanrow.
The returned
predictorsis a dict keyed by(feature_set, model); pick the best one by itsis_bestrow:best = df_eval[df_eval["is_best"]].iloc[0] print(f"best: {best['feature_set']} x {best['model']} " f"(bACC={best['balanced_accuracy_mean']:.3f})") print("predictor keys:", list(predictors)) best_predictor = predictors[(best["feature_set"], best["model"])] print("best predictor:", type(best_predictor).__name__)
best: features x SVM (bACC=0.820) predictor keys: [('features', 'RandomForest'), ('features', 'ExtraTrees'), ('features', 'SVM'), ('features', 'LogReg')] best predictor: SVC
Choosing the models.
modelsaccepts model-name strings ('rf','svm','log_reg','extra_trees'), estimator instances, or a{name: model}dict. The comparison plot is styled withfigsize, a per-modeldict_color, and abaselinechance line:# The comparison plot is styled with figsize, dict_color (keyed by model name) and a baseline line. predictors, ax, df_eval = ap.predict_samples( df_feat, df_seq, labels=labels, models={"forest": "rf", "svc_rbf": SVC(C=2.0, probability=True), "logreg": LogisticRegression(max_iter=500)}, n_cv=4, random_state=42, figsize=(7, 4), baseline=0.5, dict_color={"forest": "tab:green", "svc_rbf": "tab:blue", "logreg": "tab:orange"}) aa.display_df(df_eval, n_rows=10, show_shape=True) plt.tight_layout() plt.show()
DataFrame shape: (3, 17)
/Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn(
feature_set model n_features balanced_accuracy_mean balanced_accuracy_std accuracy_mean accuracy_std f1_mean f1_std precision_mean precision_std recall_mean recall_std roc_auc_mean roc_auc_std is_shap_ready is_best 1 features forest 10 0.800595 0.118264 0.801282 0.113409 0.805769 0.092065 0.828869 0.133854 0.803571 0.128632 0.844246 0.098184 True False 2 features svc_rbf 10 0.839286 0.109595 0.839744 0.108974 0.836905 0.103695 0.886905 0.120673 0.803571 0.128632 0.872024 0.097217 False True 3 features logreg 10 0.779762 0.118001 0.780449 0.113262 0.789744 0.091449 0.799107 0.142508 0.803571 0.128632 0.899802 0.098064 False False 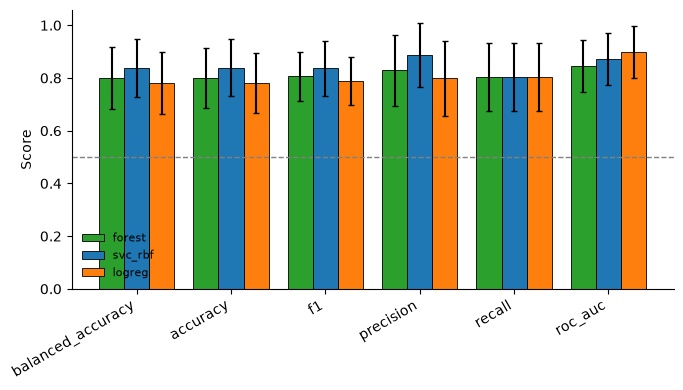
Comparing feature sets. Pass several feature sets as a
{name: df_feat}dict (or a list); every feature set is crossed with every model. This is the natural way to ask which feature set and which model work best together — e.g. a full versus a reduced feature set.n_jobssets the cores used to build the feature matrices:df_feat_top5 = df_feat.head(5) predictors, _, df_eval = ap.predict_samples( {"all10": df_feat, "top5": df_feat_top5}, df_seq, labels=labels, models=["rf", "svm"], n_cv=5, random_state=42, plot=False, n_jobs=1) aa.display_df(df_eval, n_rows=10, show_shape=True)
/Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn(
DataFrame shape: (4, 17)
/Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn( /Users/stephanbreimann/Programming/1Packages/aaanalysis/.venv/lib/python3.13/site-packages/sklearn/svm/_base.py:239: FutureWarning: The probability parameter was deprecated in 1.9 and will be removed in version 1.11. Use CalibratedClassifierCV(SVC(), ensemble=False) instead of SVC(probability=True) warnings.warn(
feature_set model n_features balanced_accuracy_mean balanced_accuracy_std accuracy_mean accuracy_std f1_mean f1_std precision_mean precision_std recall_mean recall_std roc_auc_mean roc_auc_std is_shap_ready is_best 1 all10 rf 10 0.800000 0.063246 0.800000 0.063246 0.766104 0.110364 0.886667 0.093333 0.720000 0.203961 0.816000 0.093295 True False 2 all10 svm 10 0.820000 0.074833 0.820000 0.074833 0.815051 0.072744 0.860000 0.127192 0.800000 0.126491 0.888000 0.092607 False True 3 top5 rf 5 0.700000 0.109545 0.700000 0.109545 0.696068 0.135008 0.695000 0.116619 0.720000 0.203961 0.804000 0.112712 True False 4 top5 svm 5 0.800000 0.063246 0.800000 0.063246 0.766104 0.110364 0.886667 0.093333 0.720000 0.203961 0.816000 0.114822 False False Toward explanation. The
is_shap_readypredictors (tree-based) can be handed toap.explain_featuresfor SHAP feature impact — the next step of the golden-pipeline spine. Here we list them:shap_ready = df_eval[df_eval["is_shap_ready"]][["feature_set", "model"]] aa.display_df(shap_ready, n_rows=10, show_shape=True)
DataFrame shape: (2, 2)
feature_set model 1 all10 rf 3 top5 rf